
Boston is excited to announce our partnership with DDN! Behind the scenes, our team at Boston Labs have been running benchmarks on the DDN A3I AI400X with the NVIDIA DGX-A100.
Efficient, yet powerful flexibility
DDN A3I storage solutions are fully optimised to accelerate Machine Learning and Artificial Intelligence (AI) applications, streamlining deep learning (DL) workflows for greater productivity. A3I artificial intelligence storage solutions harness the knowledge from customer-proven deployments to make AI-powered innovation easy. The AI400X is a turnkey, AI data storage infrastructure for rapid deployment, featuring faster performance, effortless scale, and simplified operations through deep integration with NVIDIA GPU systems.
DDN vs Local Storage ResNet benchmark
The following benchmark was performed to compare the suitability of a AI400X flash array to a local all-flash RAID for AI workloads.
DDN AI400X
Whether you are accelerating an analytics workload, reducing latencies for tough NoSQL databases, or beginning a Deep Learning project with modest training sets, the AI400X NVMe platform is an ideal cost-effective building block. Designed to get you the most out of your investment, the internal 192 lane PCIe Gen 3 fabric extracts the most performance from flash, enabling new bandwidth and IOPs use cases, coupled with the power of a parallel file system highly tuned for GPU workloads. Additionally, data can be accessed via standard file and object protocols for ultimate flexibility.
ResNet50
To measure the performance of the DDN AI400X system, we've employed the optimised ResNet v1.5 for MXNet implementation provided by NVIDIA through the NVIDIA GPU Cloud which you can see here.
ResNet is a shorthand for Residual Network and as the name of the network suggests, the network relies on Residual Learning (which tries to solve the challenges with training Deep Neural Networks. Such challenges include increased difficulty to train as we go deeper, as well as accuracy saturation and degradation. ResNet comes in two flavours; ResNet-50 or ResNet-152 (where ResNet 50 is a 50 layer Residual Network, and 152 is a 152 layer Residual Network). For this benchmark we focused on ResNet-50, using two of the most common batch sizes.
The benchmark was run for 30 epochs with batch sizes of 192 and 384. Each test was performed three times and the numbers reported are the average of these. The standard ImageNet 2012 dataset was used.
DGX-A100
For compute, the NVIDIA DGX-A100 was used. The DGX-A100 is a 3rd Generation integrated AI system with 5 PetaFLOPS of performance in a single node. Featuring 8x NVIDIA A100 GPUs, 15TB Gen4 NVMe SSD, 6x NVSwitches and 9x Mellanox ConnectX-6 200Gb/s network interfaces, the DGX A100 can be used for data analytics, inference and training, with the ability to split GPU resource and share it between 56 different users. The DGX A100 is elastic for scale-up and scale-out computing!
Results
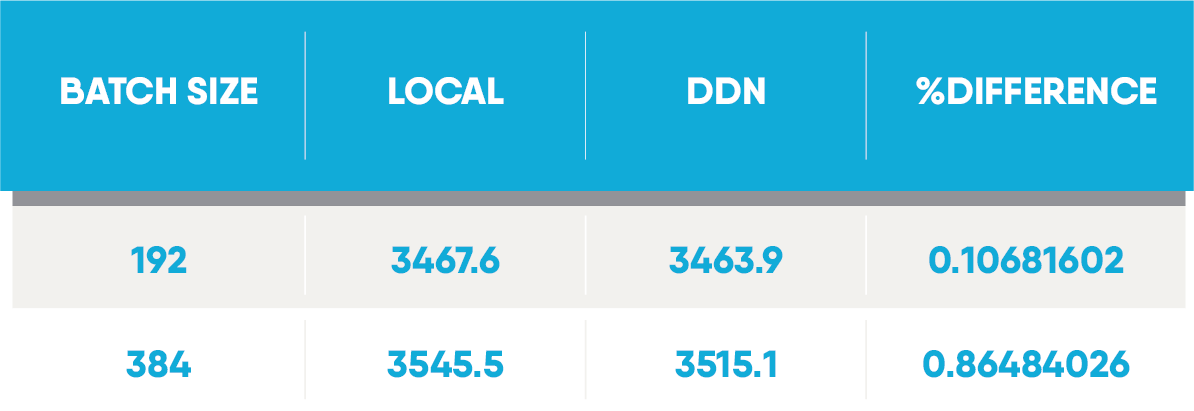
These results show that when using DDN's AI400X storage with a DGX-A100, performance is almost identical to a local all-flash RAID. With batch sizes of 192 and 384 we only observed a performance drop of 0.1% and 0.86% respectively.
Detailed steps on how the benchmark was performed can be found here.
If you have any questions about the above benchmarks or want to enquire about your own test drive, our team at Boston Labs is standing by to help you out. Our Sales team is also available to answer any queries you may have about any of the solutions mentioned at [email protected].